
Data Model Design for MongoDB
Release 3.2.3
MongoDB, Inc.
February 17, 2016

2


Contents
1 Data Modeling Introduction 3
1.1 Document Structure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Atomicity of Write Operations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.3 Document Growth . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.4 Data Use and Performance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.5 Additional Resources . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Document Validation 7
2.1 Behavior . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 Restrictions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.3 Bypass Document Validation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.4 Additional Information . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3 Data Modeling Concepts 11
3.1 Data Model Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.2 Operational Factors and Data Models . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
4 Data Model Examples and Patterns 17
4.1 Model Relationships Between Documents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.2 Model Tree Structures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.3 Model Specific Application Contexts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
5 Data Model Reference 37
5.1 Documents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.2 Database References . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
5.3 ObjectId . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5.4 BSON Types . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
i

ii

Data Model Design for MongoDB, Release 3.2.3
Data in MongoDB has a flexible schema. Collections do not enforce document structure. This flexibility gives you
data-modeling choices to match your application and its performance requirements.
Data Modeling Introduction (page 3) An introduction to data modeling in MongoDB.
Document Validation (page 7) MongoDB provides the capability to validate documents during updates and inser-
tions.
Data Modeling Concepts (page 11) The core documentation detailing the decisions you must make when determin-
ing a data model, and discussing considerations that should be taken into account.
Data Model Examples and Patterns (page 17) Examples of possible data models that you can use to structure your
MongoDB documents.
Data Model Reference (page 37) Reference material for data modeling for developers of MongoDB applications.
Contents 1

Data Model Design for MongoDB, Release 3.2.3
2 Contents

CHAPTER 1
Data Modeling Introduction
On this page
• Document Structure (page 3)
• Atomicity of Write Operations (page 5)
• Document Growth (page 5)
• Data Use and Performance (page 5)
• Additional Resources (page 5)
Data in MongoDB has a flexible schema. Unlike SQL databases, where you must determine and declare a table’s
schema before inserting data, MongoDB’s collections do not enforce document structure. This flexibility facilitates
the mapping of documents to an entity or an object. Each document can match the data fields of the represented entity,
even if the data has substantial variation. In practice, however, the documents in a collection share a similar structure.
The key challenge in data modeling is balancing the needs of the application, the performance characteristics of the
database engine, and the data retrieval patterns. When designing data models, always consider the application usage
of the data (i.e. queries, updates, and processing of the data) as well as the inherent structure of the data itself.
1.1 Document Structure
The key decision in designing data models for MongoDB applications revolves around the structure of documents and
how the application represents relationships between data. There are two tools that allow applications to represent
these relationships: references and embedded documents.
1.1.1 References
References store the relationships between data by including links or references from one document to another. Appli-
cations can resolve these references (page 40) to access the related data. Broadly, these are normalized data models.
See Normalized Data Models (page 12) for the strengths and weaknesses of using references.
1.1.2 Embedded Data
Embedded documents capture relationships between data by storing related data in a single document structure. Mon-
goDB documents make it possible to embed document structures in a field or array within a document. These denor-
malized data models allow applications to retrieve and manipulate related data in a single database operation.
3

Data Model Design for MongoDB, Release 3.2.3
4 Chapter 1. Data Modeling Introduction

Data Model Design for MongoDB, Release 3.2.3
See Embedded Data Models (page 11) for the strengths and weaknesses of embedding documents.
1.2 Atomicity of Write Operations
In MongoDB, write operations are atomic at the document level, and no single write operation can atomically affect
more than one document or more than one collection. A denormalized data model with embedded data combines
all related data for a represented entity in a single document. This facilitates atomic write operations since a single
write operation can insert or update the data for an entity. Normalizing the data would split the data across multiple
collections and would require multiple write operations that are not atomic collectively.
However, schemas that facilitate atomic writes may limit ways that applications can use the data or may limit ways to
modify applications. The Atomicity Considerations (page 14) documentation describes the challenge of designing a
schema that balances flexibility and atomicity.
1.3 Document Growth
Some updates, such as pushing elements to an array or adding new fields, increase a document’s size.
For the MMAPv1 storage engine, if the document size exceeds the allocated space for that document, MongoDB
relocates the document on disk. When using the MMAPv1 storage engine, growth consideration can affect the decision
to normalize or denormalize data. See Document Growth Considerations (page 14) for more about planning for and
managing document growth for MMAPv1.
1.4 Data Use and Performance
When designing a data model, consider how applications will use your database. For
instance, if your application only uses recently inserted documents, consider using
https://docs.mongodb.org/manual/core/capped-collections. Or if your application needs
are mainly read operations to a collection, adding indexes to support common queries can improve performance.
See Operational Factors and Data Models (page 13) for more information on these and other operational considera-
tions that affect data model designs.
1.5 Additional Resources
• Thinking in Documents Part 1 (Blog Post)
1
1
https://www.mongodb.com/blog/post/thinking-documents-part-1?jmp=docs
1.2. Atomicity of Write Operations 5

Data Model Design for MongoDB, Release 3.2.3
6 Chapter 1. Data Modeling Introduction

CHAPTER 2
Document Validation
On this page
• Behavior (page 7)
• Restrictions (page 9)
• Bypass Document Validation (page 9)
• Additional Information (page 9)
New in version 3.2.
MongoDB provides the capability to validate documents during updates and insertions. Validation rules are specified
on a per-collection basis using the validator option, which takes a document that specifies the validation rules
or expressions. Specify the expressions using any query operators, with the exception of $near, $nearSphere,
$text, and $where.
Add document validation to an existing collection using the collMod command with the validator option. You
can also specify document validation rules when creating a new collection using db.createCollection() with
the validator option, as in the following:
db.createCollection( "contacts",
{ validator: { $or:
[
{ phone: { $type: "string" } },
{ email: { $regex: /@mongodb\.com$/ } },
{ status: { $in: [ "Unknown", "Incomplete" ] } }
]
}
} )
MongoDB also provides the validationLevel option, which determines how strictly MongoDB applies valida-
tion rules to existing documents during an update, and the validationAction option, which determines whether
MongoDB should error and reject documents that violate the validation rules or warn about the violations in the
log but allow invalid documents.
2.1 Behavior
Validation occurs during updates and inserts. When you add validation to a collection, existing documents do not
undergo validation checks until modification.
7

Data Model Design for MongoDB, Release 3.2.3
2.1.1 Existing Documents
You can control how MongoDB handles existing documents using the validationLevel option.
By default, validationLevel is strict and MongoDB applies validation rules to all inserts and updates. Setting
validationLevel to moderate applies validation rules to inserts and to updates to existing documents that fulfill
the validation criteria. With the moderate level, updates to existing documents that do not fulfill the validation
criteria are not checked for validity.
Example
Consider the following documents in a contacts collection:
{
"_id": "125876"
"name": "Anne",
"phone": "+1 555 123 456",
"city": "London",
"status": "Complete"
},
{
"_id": "860000",
"name": "Ivan",
"city": "Vancouver"
}
Issue the following command to add a validator to the contacts collection:
db.runCommand( {
collMod: "contacts",
validator: { $or: [ { phone: { $exists: true } }, { email: { $exists: true } } ] },
validationLevel: "moderate"
} )
The contacts collection now has a validator with the moderate validationLevel. If you attempted to update the
document with _id of 125876, MongoDB would apply validation rules since the existing document matches the
criteria. In contrast, MongoDB will not apply validation rules to updates to the document with _id of 860000 as it
does not meet the validation rules.
To disable validation entirely, you can set validationLevel to off.
2.1.2 Accept or Reject Invalid Documents
The validationAction option determines how MongoDB handles documents that violate the validation rules.
By default, validationAction is error and MongoDB rejects any insertion or update that violates the validation
criteria. When validationAction is set to warn, MongoDB logs any violations but allows the insertion or update
to proceed.
Example
The following example creates a contacts collection with a validator that specifies that inserted or updated docu-
ments should match at least one of three following conditions:
• the phone field is a string
• the email field matches the regular expression
• the status field is either Unknown or Incomplete.
8 Chapter 2. Document Validation

Data Model Design for MongoDB, Release 3.2.3
db.createCollection( "contacts",
{
validator: { $or:
[
{ phone: { $type: "string" } },
{ email: { $regex: /@mongodb\.com$/ } },
{ status: { $in: [ "Unknown", "Incomplete" ] } }
]
},
validationAction: "warn"
}
)
With the validator in place, the following insert operation fails the validation rules, but since the
validationAction is warn, the write operation logs the failure and succeeds.
db.contacts.insert( { name: "Amanda", status: "Updated" } )
The log includes the full namespace of the collection and the document that failed the validation rules, as well as the
time of the operation:
2015-10-15T11:20:44.260-0400 W STORAGE [conn3] Document would fail validation collection: example.contacts doc: { _id: ObjectId('561fc44c067a5d85b96274e4'), name: "Amanda", status: "Updated" }
2.2 Restrictions
You cannot specify a validator for collections in the admin, local, and config databases.
You cannot specify a validator for system.
*
collections.
2.3 Bypass Document Validation
User can bypass document validation using the bypassDocumentValidation option. For a list of commands
that support the bypassDocumentValidation option, see 3.2-rel-notes-document-validation.
For deployments that have enabled access control, to bypass document validation, the authenticated user must have
bypassDocumentValidation action. The built-in roles dbAdmin and restore provide this action.
2.4 Additional Information
See also:
collMod, db.createCollection(), db.getCollectionInfos().
2.2. Restrictions 9

Data Model Design for MongoDB, Release 3.2.3
10 Chapter 2. Document Validation

CHAPTER 3
Data Modeling Concepts
Consider the following aspects of data modeling in MongoDB:
Data Model Design (page 11) Presents the different strategies that you can choose from when determining your data
model, their strengths and their weaknesses.
Operational Factors and Data Models (page 13) Details features you should keep in mind when designing your data
model, such as lifecycle management, indexing, horizontal scalability, and document growth.
For a general introduction to data modeling in MongoDB, see the Data Modeling Introduction (page 3). For example
data models, see Data Modeling Examples and Patterns (page 17).
3.1 Data Model Design
On this page
• Embedded Data Models (page 11)
• Normalized Data Models (page 12)
• Additional Resources (page 13)
Effective data models support your application needs. The key consideration for the structure of your documents is
the decision to embed (page 11) or to use references (page 12).
3.1.1 Embedded Data Models
With MongoDB, you may embed related data in a single structure or document. These schema are generally known
as “denormalized” models, and take advantage of MongoDB’s rich documents. Consider the following diagram:
Embedded data models allow applications to store related pieces of information in the same database record. As a
result, applications may need to issue fewer queries and updates to complete common operations.
In general, use embedded data models when:
• you have “contains” relationships between entities. See Model One-to-One Relationships with Embedded Doc-
uments (page 18).
• you have one-to-many relationships between entities. In these relationships the “many” or child documents
always appear with or are viewed in the context of the “one” or parent documents. See Model One-to-Many
Relationships with Embedded Documents (page 19).
11

Data Model Design for MongoDB, Release 3.2.3
In general, embedding provides better performance for read operations, as well as the ability to request and retrieve
related data in a single database operation. Embedded data models make it possible to update related data in a single
atomic write operation.
However, embedding related data in documents may lead to situations where documents grow after creation. With the
MMAPv1 storage engine, document growth can impact write performance and lead to data fragmentation.
In version 3.0.0, MongoDB uses power-of-2-allocation as the default allocation strategy for MMAPv1 in order to
account for document growth, minimizing the likelihood of data fragmentation. See power-of-2-allocation for details.
Furthermore, documents in MongoDB must be smaller than the maximum BSON document size. For bulk
binary data, consider GridFS.
To interact with embedded documents, use dot notation to “reach into” embedded documents. See query for data
in arrays and query data in embedded documents for more examples on accessing data in arrays and embedded
documents.
3.1.2 Normalized Data Models
Normalized data models describe relationships using references (page 40) between documents.
In general, use normalized data models:
• when embedding would result in duplication of data but would not provide sufficient read performance advan-
tages to outweigh the implications of the duplication.
• to represent more complex many-to-many relationships.
• to model large hierarchical data sets.
References provides more flexibility than embedding. However, client-side applications must issue follow-up queries
to resolve the references. In other words, normalized data models can require more round trips to the server.
See Model One-to-Many Relationships with Document References (page 20) for an example of referencing. For
examples of various tree models using references, see Model Tree Structures (page 22).
12 Chapter 3. Data Modeling Concepts

Data Model Design for MongoDB, Release 3.2.3
3.1.3 Additional Resources
• Thinking in Documents Part 1 (Blog Post)
1
• Thinking in Documents (Presentation)
2
• Schema Design for Time Series Data (Presentation)
3
• Socialite, the Open Source Status Feed - Storing a Social Graph (Presentation)
4
• MongoDB Rapid Start Consultation Services
5
3.2 Operational Factors and Data Models
On this page
• Document Growth (page 14)
• Atomicity (page 14)
• Sharding (page 14)
• Indexes (page 15)
• Large Number of Collections (page 15)
• Data Lifecycle Management (page 16)
1
https://www.mongodb.com/blog/post/thinking-documents-part-1?jmp=docs
2
http://www.mongodb.com/presentations/webinar-back-basics-1-thinking-documents?jmp=docs
3
http://www.mongodb.com/presentations/webinar-time-series-data-mongodb?jmp=docs
4
http://www.mongodb.com/presentations/socialite-open-source-status-feed-part-2-managing-social-graph?jmp=docs
5
https://www.mongodb.com/products/consulting?jmp=docs#rapid_start
3.2. Operational Factors and Data Models 13

Data Model Design for MongoDB, Release 3.2.3
Modeling application data for MongoDB depends on both the data itself, as well as the characteristics of MongoDB
itself. For example, different data models may allow applications to use more efficient queries, increase the throughput
of insert and update operations, or distribute activity to a sharded cluster more effectively.
These factors are operational or address requirements that arise outside of the application but impact the perfor-
mance of MongoDB based applications. When developing a data model, analyze all of your application’s read
operations and write operations in conjunction with the following considerations.
3.2.1 Document Growth
Changed in version 3.0.0.
Some updates to documents can increase the size of documents. These updates include pushing elements to an array
(i.e. $push) and adding new fields to a document.
When using the MMAPv1 storage engine, document growth can be a consideration for your data model. For
MMAPv1, if the document size exceeds the allocated space for that document, MongoDB will relocate the docu-
ment on disk. With MongoDB 3.0.0, however, the default use of the power-of-2-allocation minimizes the occurrences
of such re-allocations as well as allows for the effective reuse of the freed record space.
When using MMAPv1, if your applications require updates that will frequently cause document growth to exceeds
the current power of 2 allocation, you may want to refactor your data model to use references between data in distinct
documents rather than a denormalized data model.
You may also use a pre-allocation strategy to explicitly avoid document growth. Refer to the Pre-Aggregated Reports
Use Case
6
for an example of the pre-allocation approach to handling document growth.
See https://docs.mongodb.org/manual/core/mmapv1 for more information on MMAPv1.
3.2.2 Atomicity
In MongoDB, operations are atomic at the document level. No single write operation can change more than one
document. Operations that modify more than a single document in a collection still operate on one document at a time.
7
Ensure that your application stores all fields with atomic dependency requirements in the same document. If the
application can tolerate non-atomic updates for two pieces of data, you can store these data in separate documents.
A data model that embeds related data in a single document facilitates these kinds of atomic operations. For data mod-
els that store references between related pieces of data, the application must issue separate read and write operations
to retrieve and modify these related pieces of data.
See Model Data for Atomic Operations (page 30) for an example data model that provides atomic updates for a single
document.
3.2.3 Sharding
MongoDB uses sharding to provide horizontal scaling. These clusters support deployments with large data sets and
high-throughput operations. Sharding allows users to partition a collection within a database to distribute the collec-
tion’s documents across a number of mongod instances or shards.
To distribute data and application traffic in a sharded collection, MongoDB uses the shard key. Selecting the proper
shard key has significant implications for performance, and can enable or prevent query isolation and increased write
capacity. It is important to consider carefully the field or fields to use as the shard key.
6
https://docs.mongodb.org/ecosystem/use-cases/pre-aggregated-reports
7
Document-level atomic operations include all operations within a single MongoDB document record: operations that affect multiple embedded
documents within that single record are still atomic.
14 Chapter 3. Data Modeling Concepts

Data Model Design for MongoDB, Release 3.2.3
See https://docs.mongodb.org/manual/core/sharding-introduction and
https://docs.mongodb.org/manual/core/sharding-shard-key for more information.
3.2.4 Indexes
Use indexes to improve performance for common queries. Build indexes on fields that appear often in queries and for
all operations that return sorted results. MongoDB automatically creates a unique index on the _id field.
As you create indexes, consider the following behaviors of indexes:
• Each index requires at least 8 kB of data space.
• Adding an index has some negative performance impact for write operations. For collections with high write-
to-read ratio, indexes are expensive since each insert must also update any indexes.
• Collections with high read-to-write ratio often benefit from additional indexes. Indexes do not affect un-indexed
read operations.
• When active, each index consumes disk space and memory. This usage can be significant and should be tracked
for capacity planning, especially for concerns over working set size.
See https://docs.mongodb.org/manual/applications/indexes for more information on indexes as
well as https://docs.mongodb.org/manual/tutorial/analyze-query-plan/. Additionally, the
MongoDB database profiler may help identify inefficient queries.
3.2.5 Large Number of Collections
In certain situations, you might choose to store related information in several collections rather than in a single collec-
tion.
Consider a sample collection logs that stores log documents for various environment and applications. The logs
collection contains documents of the following form:
{ log: "dev", ts: ..., info: ... }
{ log: "debug", ts: ..., info: ...}
If the total number of documents is low, you may group documents into collection by type. For logs, consider main-
taining distinct log collections, such as logs_dev and logs_debug. The logs_dev collection would contain
only the documents related to the dev environment.
Generally, having a large number of collections has no significant performance penalty and results in very good
performance. Distinct collections are very important for high-throughput batch processing.
When using models that have a large number of collections, consider the following behaviors:
• Each collection has a certain minimum overhead of a few kilobytes.
• Each index, including the index on _id, requires at least 8 kB of data space.
• For each database, a single namespace file (i.e. <database>.ns) stores all meta-data for that database, and
each index and collection has its own entry in the namespace file. MongoDB places limits on the size
of namespace files.
• MongoDB using the mmapv1 storage engine has limits on the number of namespaces. You may
wish to know the current number of namespaces in order to determine how many additional namespaces the
database can support. To get the current number of namespaces, run the following in the mongo shell:
db.system.namespaces.count()
3.2. Operational Factors and Data Models 15

Data Model Design for MongoDB, Release 3.2.3
The limit on the number of namespaces depend on the <database>.ns size. The namespace file defaults to
16 MB.
To change the size of the new namespace file, start the server with the option --nssize <new size MB>.
For existing databases, after starting up the server with --nssize, run the db.repairDatabase() com-
mand from the mongo shell. For impacts and considerations on running db.repairDatabase(), see
repairDatabase.
3.2.6 Data Lifecycle Management
Data modeling decisions should take data lifecycle management into consideration.
The Time to Live or TTL feature of collections expires documents after a period of time. Consider using
the TTL feature if your application requires some data to persist in the database for a limited period of time.
Additionally, if your application only uses recently inserted documents, consider
https://docs.mongodb.org/manual/core/capped-collections. Capped collections provide
first-in-first-out (FIFO) management of inserted documents and efficiently support operations that insert and read
documents based on insertion order.
16 Chapter 3. Data Modeling Concepts

CHAPTER 4
Data Model Examples and Patterns
The following documents provide overviews of various data modeling patterns and common schema design consider-
ations:
Model Relationships Between Documents (page 17) Examples for modeling relationships between documents.
Model One-to-One Relationships with Embedded Documents (page 18) Presents a data model that uses em-
bedded documents (page 11) to describe one-to-one relationships between connected data.
Model One-to-Many Relationships with Embedded Documents (page 19) Presents a data model that uses em-
bedded documents (page 11) to describe one-to-many relationships between connected data.
Model One-to-Many Relationships with Document References (page 20) Presents a data model that uses ref-
erences (page 12) to describe one-to-many relationships between documents.
Model Tree Structures (page 22) Examples for modeling tree structures.
Model Tree Structures with Parent References (page 23) Presents a data model that organizes documents in a
tree-like structure by storing references (page 12) to “parent” nodes in “child” nodes.
Model Tree Structures with Child References (page 24) Presents a data model that organizes documents in a
tree-like structure by storing references (page 12) to “child” nodes in “parent” nodes.
See Model Tree Structures (page 22) for additional examples of data models for tree structures.
Model Specific Application Contexts (page 30) Examples for models for specific application contexts.
Model Data for Atomic Operations (page 30) Illustrates how embedding fields related to an atomic update
within the same document ensures that the fields are in sync.
Model Data to Support Keyword Search (page 31) Describes one method for supporting keyword search by
storing keywords in an array in the same document as the text field. Combined with a multi-key index, this
pattern can support application’s keyword search operations.
4.1 Model Relationships Between Documents
Model One-to-One Relationships with Embedded Documents (page 18) Presents a data model that uses embedded
documents (page 11) to describe one-to-one relationships between connected data.
Model One-to-Many Relationships with Embedded Documents (page 19) Presents a data model that uses embedded
documents (page 11) to describe one-to-many relationships between connected data.
Model One-to-Many Relationships with Document References (page 20) Presents a data model that uses references
(page 12) to describe one-to-many relationships between documents.
17

Data Model Design for MongoDB, Release 3.2.3
4.1.1 Model One-to-One Relationships with Embedded Documents
On this page
• Overview (page 18)
• Pattern (page 18)
Overview
Data in MongoDB has a flexible schema. Collections do not enforce document structure. Decisions that affect how
you model data can affect application performance and database capacity. See Data Modeling Concepts (page 11) for
a full high level overview of data modeling in MongoDB.
This document describes a data model that uses embedded (page 11) documents to describe relationships between
connected data.
Pattern
Consider the following example that maps patron and address relationships. The example illustrates the advantage of
embedding over referencing if you need to view one data entity in context of the other. In this one-to-one relationship
between patron and address data, the address belongs to the patron.
In the normalized data model, the address document contains a reference to the patron document.
{
_id: "joe",
name: "Joe Bookreader"
}
{
patron_id: "joe",
street: "123 Fake Street",
city: "Faketon",
state: "MA",
zip: "12345"
}
If the address data is frequently retrieved with the name information, then with referencing, your application needs
to issue multiple queries to resolve the reference. The better data model would be to embed the address data in the
patron data, as in the following document:
{
_id: "joe",
name: "Joe Bookreader",
address: {
street: "123 Fake Street",
city: "Faketon",
state: "MA",
zip: "12345"
}
}
With the embedded data model, your application can retrieve the complete patron information with one query.
18 Chapter 4. Data Model Examples and Patterns

Data Model Design for MongoDB, Release 3.2.3
4.1.2 Model One-to-Many Relationships with Embedded Documents
On this page
• Overview (page 19)
• Pattern (page 19)
Overview
Data in MongoDB has a flexible schema. Collections do not enforce document structure. Decisions that affect how
you model data can affect application performance and database capacity. See Data Modeling Concepts (page 11) for
a full high level overview of data modeling in MongoDB.
This document describes a data model that uses embedded (page 11) documents to describe relationships between
connected data.
Pattern
Consider the following example that maps patron and multiple address relationships. The example illustrates the
advantage of embedding over referencing if you need to view many data entities in context of another. In this one-to-
many relationship between patron and address data, the patron has multiple address entities.
In the normalized data model, the address documents contain a reference to the patron document.
{
_id: "joe",
name: "Joe Bookreader"
}
{
patron_id: "joe",
street: "123 Fake Street",
city: "Faketon",
state: "MA",
zip: "12345"
}
{
patron_id: "joe",
street: "1 Some Other Street",
city: "Boston",
state: "MA",
zip: "12345"
}
If your application frequently retrieves the address data with the name information, then your application needs
to issue multiple queries to resolve the references. A more optimal schema would be to embed the address data
entities in the patron data, as in the following document:
{
_id: "joe",
name: "Joe Bookreader",
addresses: [
{
street: "123 Fake Street",
4.1. Model Relationships Between Documents 19

Data Model Design for MongoDB, Release 3.2.3
city: "Faketon",
state: "MA",
zip: "12345"
},
{
street: "1 Some Other Street",
city: "Boston",
state: "MA",
zip: "12345"
}
]
}
With the embedded data model, your application can retrieve the complete patron information with one query.
4.1.3 Model One-to-Many Relationships with Document References
On this page
• Overview (page 20)
• Pattern (page 20)
Overview
Data in MongoDB has a flexible schema. Collections do not enforce document structure. Decisions that affect how
you model data can affect application performance and database capacity. See Data Modeling Concepts (page 11) for
a full high level overview of data modeling in MongoDB.
This document describes a data model that uses references (page 12) between documents to describe relationships
between connected data.
Pattern
Consider the following example that maps publisher and book relationships. The example illustrates the advantage of
referencing over embedding to avoid repetition of the publisher information.
Embedding the publisher document inside the book document would lead to repetition of the publisher data, as the
following documents show:
{
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher: {
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
}
{
20 Chapter 4. Data Model Examples and Patterns

Data Model Design for MongoDB, Release 3.2.3
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published_date: ISODate("2011-05-06"),
pages: 68,
language: "English",
publisher: {
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
}
To avoid repetition of the publisher data, use references and keep the publisher information in a separate collection
from the book collection.
When using references, the growth of the relationships determine where to store the reference. If the number of books
per publisher is small with limited growth, storing the book reference inside the publisher document may sometimes
be useful. Otherwise, if the number of books per publisher is unbounded, this data model would lead to mutable,
growing arrays, as in the following example:
{
name: "O'Reilly Media",
founded: 1980,
location: "CA",
books: [12346789, 234567890, ...]
}
{
_id: 123456789,
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English"
}
{
_id: 234567890,
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published_date: ISODate("2011-05-06"),
pages: 68,
language: "English"
}
To avoid mutable, growing arrays, store the publisher reference inside the book document:
{
_id: "oreilly",
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
{
_id: 123456789,
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
4.1. Model Relationships Between Documents 21

Data Model Design for MongoDB, Release 3.2.3
pages: 216,
language: "English",
publisher_id: "oreilly"
}
{
_id: 234567890,
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published_date: ISODate("2011-05-06"),
pages: 68,
language: "English",
publisher_id: "oreilly"
}
4.2 Model Tree Structures
MongoDB allows various ways to use tree data structures to model large hierarchical or nested data relationships.
Model Tree Structures with Parent References (page 23) Presents a data model that organizes documents in a tree-
like structure by storing references (page 12) to “parent” nodes in “child” nodes.
Model Tree Structures with Child References (page 24) Presents a data model that organizes documents in a tree-
like structure by storing references (page 12) to “child” nodes in “parent” nodes.
22 Chapter 4. Data Model Examples and Patterns

Data Model Design for MongoDB, Release 3.2.3
Model Tree Structures with an Array of Ancestors (page 25) Presents a data model that organizes documents in a
tree-like structure by storing references (page 12) to “parent” nodes and an array that stores all ancestors.
Model Tree Structures with Materialized Paths (page 27) Presents a data model that organizes documents in a tree-
like structure by storing full relationship paths between documents. In addition to the tree node, each document
stores the _id of the nodes ancestors or path as a string.
Model Tree Structures with Nested Sets (page 29) Presents a data model that organizes documents in a tree-like
structure using the Nested Sets pattern. This optimizes discovering subtrees at the expense of tree mutability.
4.2.1 Model Tree Structures with Parent References
On this page
• Overview (page 23)
• Pattern (page 23)
Overview
Data in MongoDB has a flexible schema. Collections do not enforce document structure. Decisions that affect how
you model data can affect application performance and database capacity. See Data Modeling Concepts (page 11) for
a full high level overview of data modeling in MongoDB.
This document describes a data model that describes a tree-like structure in MongoDB documents by storing references
(page 12) to “parent” nodes in children nodes.
Pattern
The Parent References pattern stores each tree node in a document; in addition to the tree node, the document stores
the id of the node’s parent.
Consider the following hierarchy of categories:
The following example models the tree using Parent References, storing the reference to the parent category in the
field parent:
db.categories.insert( { _id: "MongoDB", parent: "Databases" } )
db.categories.insert( { _id: "dbm", parent: "Databases" } )
db.categories.insert( { _id: "Databases", parent: "Programming" } )
db.categories.insert( { _id: "Languages", parent: "Programming" } )
db.categories.insert( { _id: "Programming", parent: "Books" } )
db.categories.insert( { _id: "Books", parent: null } )
• The query to retrieve the parent of a node is fast and straightforward:
db.categories.findOne( { _id: "MongoDB" } ).parent
• You can create an index on the field parent to enable fast search by the parent node:
db.categories.createIndex( { parent: 1 } )
• You can query by the parent field to find its immediate children nodes:
db.categories.find( { parent: "Databases" } )
The Parent Links pattern provides a simple solution to tree storage but requires multiple queries to retrieve subtrees.
4.2. Model Tree Structures 23

Data Model Design for MongoDB, Release 3.2.3
4.2.2 Model Tree Structures with Child References
On this page
• Overview (page 24)
• Pattern (page 24)
Overview
Data in MongoDB has a flexible schema. Collections do not enforce document structure. Decisions that affect how
you model data can affect application performance and database capacity. See Data Modeling Concepts (page 11) for
a full high level overview of data modeling in MongoDB.
This document describes a data model that describes a tree-like structure in MongoDB documents by storing references
(page 12) in the parent-nodes to children nodes.
Pattern
The Child References pattern stores each tree node in a document; in addition to the tree node, document stores in an
array the id(s) of the node’s children.
Consider the following hierarchy of categories:
24 Chapter 4. Data Model Examples and Patterns
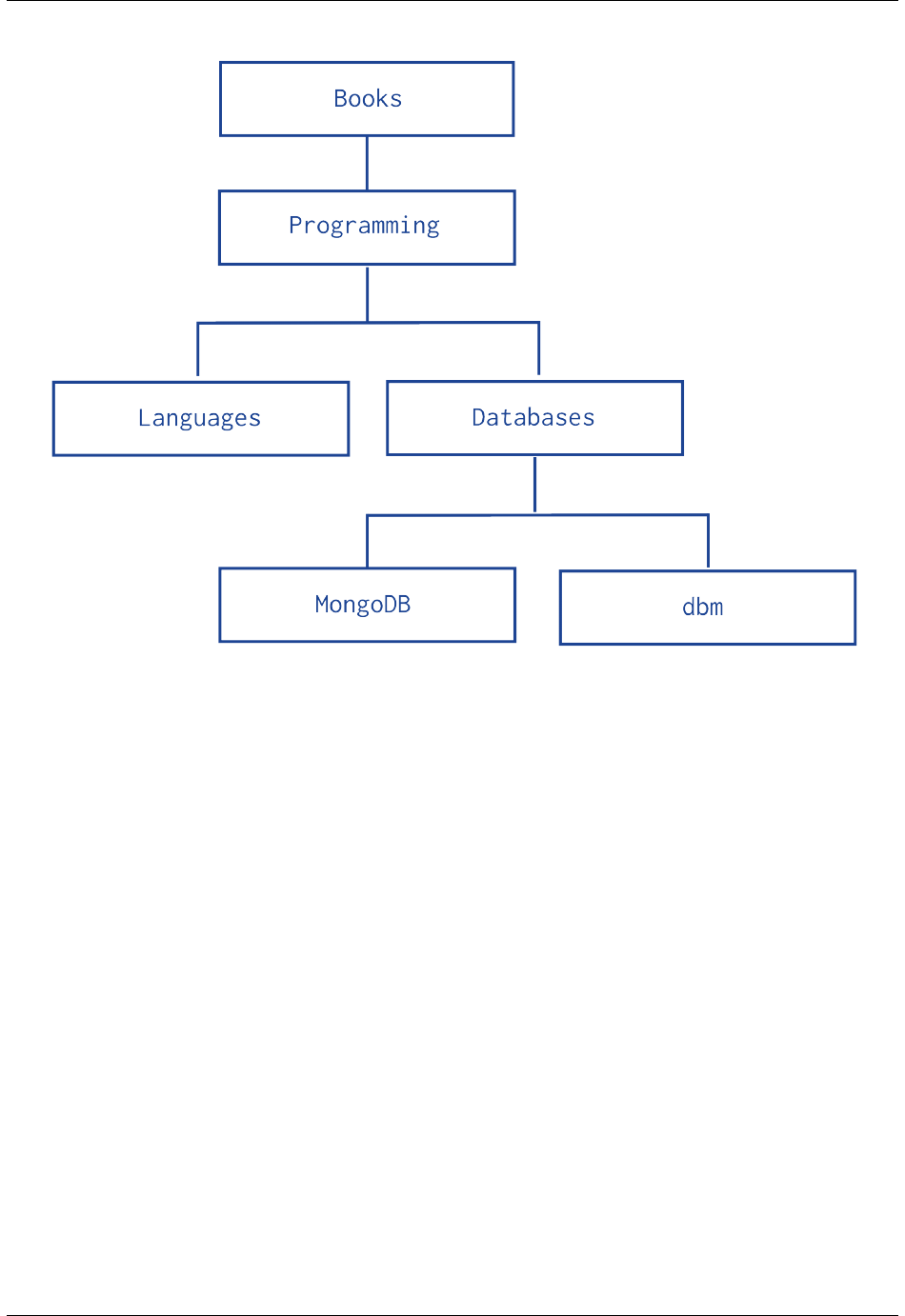
Data Model Design for MongoDB, Release 3.2.3
The following example models the tree using Child References, storing the reference to the node’s children in the field
children:
db.categories.insert( { _id: "MongoDB", children: [] } )
db.categories.insert( { _id: "dbm", children: [] } )
db.categories.insert( { _id: "Databases", children: [ "MongoDB", "dbm" ] } )
db.categories.insert( { _id: "Languages", children: [] } )
db.categories.insert( { _id: "Programming", children: [ "Databases", "Languages" ] } )
db.categories.insert( { _id: "Books", children: [ "Programming" ] } )
• The query to retrieve the immediate children of a node is fast and straightforward:
db.categories.findOne( { _id: "Databases" } ).children
• You can create an index on the field children to enable fast search by the child nodes:
db.categories.createIndex( { children: 1 } )
• You can query for a node in the children field to find its parent node as well as its siblings:
db.categories.find( { children: "MongoDB" } )
The Child References pattern provides a suitable solution to tree storage as long as no operations on subtrees are
necessary. This pattern may also provide a suitable solution for storing graphs where a node may have multiple
parents.
4.2.3 Model Tree Structures with an Array of Ancestors
4.2. Model Tree Structures 25

Data Model Design for MongoDB, Release 3.2.3
On this page
• Overview (page 26)
• Pattern (page 26)
Overview
Data in MongoDB has a flexible schema. Collections do not enforce document structure. Decisions that affect how
you model data can affect application performance and database capacity. See Data Modeling Concepts (page 11) for
a full high level overview of data modeling in MongoDB.
This document describes a data model that describes a tree-like structure in MongoDB documents using references
(page 12) to parent nodes and an array that stores all ancestors.
Pattern
The Array of Ancestors pattern stores each tree node in a document; in addition to the tree node, document stores in
an array the id(s) of the node’s ancestors or path.
Consider the following hierarchy of categories:
The following example models the tree using Array of Ancestors. In addition to the ancestors field, these docu-
ments also store the reference to the immediate parent category in the parent field:
26 Chapter 4. Data Model Examples and Patterns

Data Model Design for MongoDB, Release 3.2.3
db.categories.insert( { _id: "MongoDB", ancestors: [ "Books", "Programming", "Databases" ], parent: "Databases" } )
db.categories.insert( { _id: "dbm", ancestors: [ "Books", "Programming", "Databases" ], parent: "Databases" } )
db.categories.insert( { _id: "Databases", ancestors: [ "Books", "Programming" ], parent: "Programming" } )
db.categories.insert( { _id: "Languages", ancestors: [ "Books", "Programming" ], parent: "Programming" } )
db.categories.insert( { _id: "Programming", ancestors: [ "Books" ], parent: "Books" } )
db.categories.insert( { _id: "Books", ancestors: [ ], parent: null } )
• The query to retrieve the ancestors or path of a node is fast and straightforward:
db.categories.findOne( { _id: "MongoDB" } ).ancestors
• You can create an index on the field ancestors to enable fast search by the ancestors nodes:
db.categories.createIndex( { ancestors: 1 } )
• You can query by the field ancestors to find all its descendants:
db.categories.find( { ancestors: "Programming" } )
The Array of Ancestors pattern provides a fast and efficient solution to find the descendants and the ancestors of a node
by creating an index on the elements of the ancestors field. This makes Array of Ancestors a good choice for working
with subtrees.
The Array of Ancestors pattern is slightly slower than the Materialized Paths (page 27) pattern but is more straightfor-
ward to use.
4.2.4 Model Tree Structures with Materialized Paths
On this page
• Overview (page 27)
• Pattern (page 27)
Overview
Data in MongoDB has a flexible schema. Collections do not enforce document structure. Decisions that affect how
you model data can affect application performance and database capacity. See Data Modeling Concepts (page 11) for
a full high level overview of data modeling in MongoDB.
This document describes a data model that describes a tree-like structure in MongoDB documents by storing full
relationship paths between documents.
Pattern
The Materialized Paths pattern stores each tree node in a document; in addition to the tree node, document stores as
a string the id(s) of the node’s ancestors or path. Although the Materialized Paths pattern requires additional steps of
working with strings and regular expressions, the pattern also provides more flexibility in working with the path, such
as finding nodes by partial paths.
Consider the following hierarchy of categories:
The following example models the tree using Materialized Paths, storing the path in the field path; the path string
uses the comma , as a delimiter:
4.2. Model Tree Structures 27

Data Model Design for MongoDB, Release 3.2.3
db.categories.insert( { _id: "Books", path: null } )
db.categories.insert( { _id: "Programming", path: ",Books," } )
db.categories.insert( { _id: "Databases", path: ",Books,Programming," } )
db.categories.insert( { _id: "Languages", path: ",Books,Programming," } )
db.categories.insert( { _id: "MongoDB", path: ",Books,Programming,Databases," } )
db.categories.insert( { _id: "dbm", path: ",Books,Programming,Databases," } )
• You can query to retrieve the whole tree, sorting by the field path:
db.categories.find().sort( { path: 1 } )
• You can use regular expressions on the path field to find the descendants of Programming:
db.categories.find( { path: /,Programming,/ } )
• You can also retrieve the descendants of Books where the Books is also at the topmost level of the hierarchy:
db.categories.find( { path: /^,Books,/ } )
• To create an index on the field path use the following invocation:
db.categories.createIndex( { path: 1 } )
This index may improve performance depending on the query:
– For queries from the root Books sub-tree (e.g. https://docs.mongodb.org/manual/^,Books,/
or https://docs.mongodb.org/manual/^,Books,Programming,/), an index on the path
field improves the query performance significantly.
28 Chapter 4. Data Model Examples and Patterns

Data Model Design for MongoDB, Release 3.2.3
– For queries of sub-trees where the path from the root is not provided in the query (e.g.
https://docs.mongodb.org/manual/,Databases,/), or similar queries of sub-trees, where
the node might be in the middle of the indexed string, the query must inspect the entire index.
For these queries an index may provide some performance improvement if the index is significantly smaller
than the entire collection.
4.2.5 Model Tree Structures with Nested Sets
On this page
• Overview (page 29)
• Pattern (page 29)
Overview
Data in MongoDB has a flexible schema. Collections do not enforce document structure. Decisions that affect how
you model data can affect application performance and database capacity. See Data Modeling Concepts (page 11) for
a full high level overview of data modeling in MongoDB.
This document describes a data model that describes a tree like structure that optimizes discovering subtrees at the
expense of tree mutability.
Pattern
The Nested Sets pattern identifies each node in the tree as stops in a round-trip traversal of the tree. The application
visits each node in the tree twice; first during the initial trip, and second during the return trip. The Nested Sets pattern
stores each tree node in a document; in addition to the tree node, document stores the id of node’s parent, the node’s
initial stop in the left field, and its return stop in the right field.
Consider the following hierarchy of categories:
The following example models the tree using Nested Sets:
db.categories.insert( { _id: "Books", parent: 0, left: 1, right: 12 } )
db.categories.insert( { _id: "Programming", parent: "Books", left: 2, right: 11 } )
db.categories.insert( { _id: "Languages", parent: "Programming", left: 3, right: 4 } )
db.categories.insert( { _id: "Databases", parent: "Programming", left: 5, right: 10 } )
db.categories.insert( { _id: "MongoDB", parent: "Databases", left: 6, right: 7 } )
db.categories.insert( { _id: "dbm", parent: "Databases", left: 8, right: 9 } )
You can query to retrieve the descendants of a node:
var databaseCategory = db.categories.findOne( { _id: "Databases" } );
db.categories.find( { left: { $gt: databaseCategory.left }, right: { $lt: databaseCategory.right } } );
The Nested Sets pattern provides a fast and efficient solution for finding subtrees but is inefficient for modifying the
tree structure. As such, this pattern is best for static trees that do not change.
4.2. Model Tree Structures 29

Data Model Design for MongoDB, Release 3.2.3
4.3 Model Specific Application Contexts
Model Data for Atomic Operations (page 30) Illustrates how embedding fields related to an atomic update within the
same document ensures that the fields are in sync.
Model Data to Support Keyword Search (page 31) Describes one method for supporting keyword search by storing
keywords in an array in the same document as the text field. Combined with a multi-key index, this pattern can
support application’s keyword search operations.
Model Monetary Data (page 32) Describes two methods to model monetary data in MongoDB.
Model Time Data (page 34) Describes how to deal with local time in MongoDB.
4.3.1 Model Data for Atomic Operations
On this page
• Pattern (page 30)
Pattern
In MongoDB, write operations, e.g. db.collection.update(), db.collection.findAndModify(),
db.collection.remove(), are atomic on the level of a single document. For fields that must be updated to-
gether, embedding the fields within the same document ensures that the fields can be updated atomically.
For example, consider a situation where you need to maintain information on books, including the number of copies
available for checkout as well as the current checkout information.
30 Chapter 4. Data Model Examples and Patterns

Data Model Design for MongoDB, Release 3.2.3
The available copies of the book and the checkout information should be in sync. As such, embedding the
available field and the checkout field within the same document ensures that you can update the two fields
atomically.
{
_id: 123456789,
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher_id: "oreilly",
available: 3,
checkout: [ { by: "joe", date: ISODate("2012-10-15") } ]
}
Then to update with new checkout information, you can use the db.collection.update() method to atomically
update both the available field and the checkout field:
db.books.update (
{ _id: 123456789, available: { $gt: 0 } },
{
$inc: { available: -1 },
$push: { checkout: { by: "abc", date: new Date() } }
}
)
The operation returns a WriteResult() object that contains information on the status of the operation:
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
The nMatched field shows that 1 document matched the update condition, and nModified shows that the operation
updated 1 document.
If no document matched the update condition, then nMatched and nModified would be 0 and would indicate that
you could not check out the book.
4.3.2 Model Data to Support Keyword Search
On this page
• Pattern (page 32)
• Limitations of Keyword Indexes (page 32)
Note: Keyword search is not the same as text search or full text search, and does not provide stemming or other
text-processing features. See the Limitations of Keyword Indexes (page 32) section for more information.
In 2.4, MongoDB provides a text search feature. See https://docs.mongodb.org/manual/core/index-text
for more information.
If your application needs to perform queries on the content of a field that holds text you can perform exact matches
on the text or use $regex to use regular expression pattern matches. However, for many operations on text, these
methods do not satisfy application requirements.
This pattern describes one method for supporting keyword search using MongoDB to support application search
functionality, that uses keywords stored in an array in the same document as the text field. Combined with a multi-key
4.3. Model Specific Application Contexts 31

Data Model Design for MongoDB, Release 3.2.3
index, this pattern can support application’s keyword search operations.
Pattern
To add structures to your document to support keyword-based queries, create an array field in your documents and add
the keywords as strings in the array. You can then create a multi-key index on the array and create queries that select
values from the array.
Example
Given a collection of library volumes that you want to provide topic-based search. For each volume, you add the array
topics, and you add as many keywords as needed for a given volume.
For the Moby-Dick volume you might have the following document:
{ title : "Moby-Dick" ,
author : "Herman Melville" ,
published : 1851 ,
ISBN : 0451526996 ,
topics : [ "whaling" , "allegory" , "revenge" , "American" ,
"novel" , "nautical" , "voyage" , "Cape Cod" ]
}
You then create a multi-key index on the topics array:
db.volumes.createIndex( { topics: 1 } )
The multi-key index creates separate index entries for each keyword in the topics array. For example the index
contains one entry for whaling and another for allegory.
You then query based on the keywords. For example:
db.volumes.findOne( { topics : "voyage" }, { title: 1 } )
Note: An array with a large number of elements, such as one with several hundreds or thousands of keywords will
incur greater indexing costs on insertion.
Limitations of Keyword Indexes
MongoDB can support keyword searches using specific data models and multi-key indexes; however, these keyword
indexes are not sufficient or comparable to full-text products in the following respects:
• Stemming. Keyword queries in MongoDB can not parse keywords for root or related words.
• Synonyms. Keyword-based search features must provide support for synonym or related queries in the applica-
tion layer.
• Ranking. The keyword look ups described in this document do not provide a way to weight results.
• Asynchronous Indexing. MongoDB builds indexes synchronously, which means that the indexes used for key-
word indexes are always current and can operate in real-time. However, asynchronous bulk indexes may be
more efficient for some kinds of content and workloads.
4.3.3 Model Monetary Data
32 Chapter 4. Data Model Examples and Patterns

Data Model Design for MongoDB, Release 3.2.3
On this page
• Overview (page 33)
• Use Cases for Exact Precision Model (page 33)
• Use Cases for Arbitrary Precision Model (page 33)
• Exact Precision (page 33)
• Arbitrary Precision (page 34)
Overview
MongoDB stores numeric data as either IEEE 754 standard 64-bit floating point numbers or as 32-bit or 64-bit signed
integers. Applications that handle monetary data often require capturing fractional units of currency. However, arith-
metic on floating point numbers, as implemented in modern hardware, often does not conform to requirements for
monetary arithmetic. In addition, some fractional numeric quantities, such as one third and one tenth, have no exact
representation in binary floating point numbers.
Note: Arithmetic mentioned on this page refers to server-side arithmetic performed by mongod or mongos, and not
to client-side arithmetic.
This document describes two ways to model monetary data in MongoDB:
• Exact Precision (page 33) which multiplies the monetary value by a power of 10.
• Arbitrary Precision (page 34) which uses two fields for the value: one field to store the exact monetary value as
a non-numeric and another field to store a floating point approximation of the value.
Use Cases for Exact Precision Model
If you regularly need to perform server-side arithmetic on monetary data, the exact precision model may be appropriate.
For instance:
• If you need to query the database for exact, mathematically valid matches, use Exact Precision (page 33).
• If you need to be able to do server-side arithmetic, e.g., $inc, $mul, and aggregation framework
arithmetic, use Exact Precision (page 33).
Use Cases for Arbitrary Precision Model
If there is no need to perform server-side arithmetic on monetary data, modeling monetary data using the arbitrary
precision model may be suitable. For instance:
• If you need to handle arbitrary or unforeseen number of precision, see Arbitrary Precision (page 34).
• If server-side approximations are sufficient, possibly with client-side post-processing, see Arbitrary Precision
(page 34).
Exact Precision
To model monetary data using the exact precision model:
1. Determine the maximum precision needed for the monetary value. For example, your application may require
precision down to the tenth of one cent for monetary values in USD currency.
4.3. Model Specific Application Contexts 33

Data Model Design for MongoDB, Release 3.2.3
2. Convert the monetary value into an integer by multiplying the value by a power of 10 that ensures the maximum
precision needed becomes the least significant digit of the integer. For example, if the required maximum
precision is the tenth of one cent, multiply the monetary value by 1000.
3. Store the converted monetary value.
For example, the following scales 9.99 USD by 1000 to preserve precision up to one tenth of a cent.
{ price: 9990, currency: "USD" }
The model assumes that for a given currency value:
• The scale factor is consistent for a currency; i.e. same scaling factor for a given currency.
• The scale factor is a constant and known property of the currency; i.e applications can determine the scale factor
from the currency.
When using this model, applications must be consistent in performing the appropriate scaling of the values.
For use cases of this model, see Use Cases for Exact Precision Model (page 33).
Arbitrary Precision
To model monetary data using the arbitrary precision model, store the value in two fields:
1. In one field, encode the exact monetary value as a non-numeric data type; e.g., BinData or a string.
2. In the second field, store a double-precision floating point approximation of the exact value.
The following example uses the arbitrary precision model to store 9.99 USD for the price and 0.25 USD for the
fee:
{
price: { display: "9.99", approx: 9.9900000000000002, currency: "USD" },
fee: { display: "0.25", approx: 0.2499999999999999, currency: "USD" }
}
With some care, applications can perform range and sort queries on the field with the numeric approximation. How-
ever, the use of the approximation field for the query and sort operations requires that applications perform client-side
post-processing to decode the non-numeric representation of the exact value and then filter out the returned documents
based on the exact monetary value.
For use cases of this model, see Use Cases for Arbitrary Precision Model (page 33).
4.3.4 Model Time Data
On this page
• Overview (page 34)
• Example (page 35)
Overview
MongoDB stores times in UTC (page 48) by default, and will convert any local time representations into this form.
Applications that must operate or report on some unmodified local time value may store the time zone alongside the
UTC timestamp, and compute the original local time in their application logic.
34 Chapter 4. Data Model Examples and Patterns

Data Model Design for MongoDB, Release 3.2.3
Example
In the MongoDB shell, you can store both the current date and the current client’s offset from UTC.
var now = new Date();
db.data.save( { date: now,
offset: now.getTimezoneOffset() } );
You can reconstruct the original local time by applying the saved offset:
var record = db.data.findOne();
var localNow = new Date( record.date.getTime() - ( record.offset
*
60000 ) );
4.3. Model Specific Application Contexts 35

Data Model Design for MongoDB, Release 3.2.3
36 Chapter 4. Data Model Examples and Patterns

CHAPTER 5
Data Model Reference
Documents (page 37) MongoDB stores all data in documents, which are JSON-style data structures composed of
field-and-value pairs.
Database References (page 40) Discusses manual references and DBRefs, which MongoDB can use to represent
relationships between documents.
ObjectId (page 43) A 12-byte BSON type that MongoDB uses as the default value for its documents’ _id field if the
_id field is not specified.
BSON Types (page 46) Outlines the unique BSON types used by MongoDB. See BSONspec.org
1
for the complete
BSON specification.
5.1 Documents
On this page
• Document Format (page 38)
• Document Structure (page 38)
• Field Names (page 38)
• Field Value Limit (page 39)
• Document Limitations (page 39)
• The _id Field (page 39)
• Dot Notation (page 40)
• Additional Resources (page 40)
MongoDB stores all data in documents, which are JSON-style data structures composed of field-and-value pairs:
{ "item": "pencil", "qty": 500, "type": "no.2" }
Most user-accessible data structures in MongoDB are documents, including:
• All database records.
• Query selectors, which define what records to select for read, update, and delete operations.
• Update definitions, which define what fields to modify during an update.
• Index specifications, which define what fields to index.
1
http://bsonspec.org/
37

Data Model Design for MongoDB, Release 3.2.3
• Data output by MongoDB for reporting and configuration, such as the output of the serverStatus and the
replica set configuration document.
5.1.1 Document Format
MongoDB stores documents on disk in the BSON serialization format. BSON is a binary representation of JSON
documents, though it contains more data types than JSON. For the BSON spec, see bsonspec.org
2
. See also BSON
Types (page 46).
The mongo JavaScript shell and the MongoDB language drivers translate between BSON and the language-
specific document representation.
5.1.2 Document Structure
MongoDB documents are composed of field-and-value pairs and have the following structure:
{
field1: value1,
field2: value2,
field3: value3,
...
fieldN: valueN
}
The value of a field can be any of the BSON data types (page 46), including other documents, arrays, and arrays of
documents. The following document contains values of varying types:
var mydoc = {
_id: ObjectId("5099803df3f4948bd2f98391"),
name: { first: "Alan", last: "Turing" },
birth: new Date('Jun 23, 1912'),
death: new Date('Jun 07, 1954'),
contribs: [ "Turing machine", "Turing test", "Turingery" ],
views : NumberLong(1250000)
}
The above fields have the following data types:
• _id holds an ObjectId.
• name holds an embedded document that contains the fields first and last.
• birth and death hold values of the Date type.
• contribs holds an array of strings.
• views holds a value of the NumberLong type.
5.1.3 Field Names
Field names are strings.
Documents (page 37) have the following restrictions on field names:
• The field name _id is reserved for use as a primary key; its value must be unique in the collection, is immutable,
and may be of any type other than an array.
2
http://bsonspec.org/
38 Chapter 5. Data Model Reference

Data Model Design for MongoDB, Release 3.2.3
• The field names cannot start with the dollar sign ($) character.
• The field names cannot contain the dot (.) character.
• The field names cannot contain the null character.
BSON documents may have more than one field with the same name. Most MongoDB interfaces, however,
represent MongoDB with a structure (e.g. a hash table) that does not support duplicate field names. If you need to
manipulate documents that have more than one field with the same name, see the driver documentation for
your driver.
Some documents created by internal MongoDB processes may have duplicate fields, but no MongoDB process will
ever add duplicate fields to an existing user document.
5.1.4 Field Value Limit
For indexed collections, the values for the indexed fields have a Maximum Index Key Length limit.
See Maximum Index Key Length for details.
5.1.5 Document Limitations
Documents have the following attributes:
Document Size Limit
The maximum BSON document size is 16 megabytes.
The maximum document size helps ensure that a single document cannot use excessive amount of RAM or, during
transmission, excessive amount of bandwidth. To store documents larger than the maximum size, MongoDB provides
the GridFS API. See mongofiles and the documentation for your driver for more information about GridFS.
Document Field Order
MongoDB preserves the order of the document fields following write operations except for the following cases:
• The _id field is always the first field in the document.
• Updates that include renaming of field names may result in the reordering of fields in the document.
Changed in version 2.6: Starting in version 2.6, MongoDB actively attempts to preserve the field order in a document.
Before version 2.6, MongoDB did not actively preserve the order of the fields in a document.
5.1.6 The _id Field
The _id field has the following behavior and constraints:
• By default, MongoDB creates a unique index on the _id field during the creation of a collection.
• The _id field is always the first field in the documents. If the server receives a document that does not have the
_id field first, then the server will move the field to the beginning.
• The _id field may contain values of any BSON data type (page 46), other than an array.
Warning: To ensure functioning replication, do not store values that are of the BSON regular expression
type in the _id field.
5.1. Documents 39

Data Model Design for MongoDB, Release 3.2.3
The following are common options for storing values for _id:
• Use an ObjectId (page 43).
• Use a natural unique identifier, if available. This saves space and avoids an additional index.
• Generate an auto-incrementing number. See https://docs.mongodb.org/manual/tutorial/create-an-auto-incrementing-field.
• Generate a UUID in your application code. For a more efficient storage of the UUID values in the collection
and in the _id index, store the UUID as a value of the BSON BinData type.
Index keys that are of the BinData type are more efficiently stored in the index if:
– the binary subtype value is in the range of 0-7 or 128-135, and
– the length of the byte array is: 0, 1, 2, 3, 4, 5, 6, 7, 8, 10, 12, 14, 16, 20, 24, or 32.
• Use your driver’s BSON UUID facility to generate UUIDs. Be aware that driver implementations may imple-
ment UUID serialization and deserialization logic differently, which may not be fully compatible with other
drivers. See your driver documentation
3
for information concerning UUID interoperability.
Note: Most MongoDB driver clients will include the _id field and generate an ObjectId before sending the insert
operation to MongoDB; however, if the client sends a document without an _id field, the mongod will add the _id
field and generate the ObjectId.
5.1.7 Dot Notation
MongoDB uses the dot notation to access the elements of an array and to access the fields of an embedded document.
To access an element of an array by the zero-based index position, concatenate the array name with the dot (.) and
zero-based index position, and enclose in quotes:
'<array>.<index>'
See also $ positional operator for update operations and $ projection operator when array index position is unknown.
To access a field of an embedded document with dot-notation, concatenate the embedded document name with the dot
(.) and the field name, and enclose in quotes:
'<embedded document>.<field>'
See also:
• read-operations-embedded-documents for dot notation examples with embedded documents.
• read-operations-arrays for dot notation examples with arrays.
5.1.8 Additional Resources
• Thinking in Documents Part 1 (Blog Post)
4
5.2 Database References
3
https://api.mongodb.org/
4
https://www.mongodb.com/blog/post/thinking-documents-part-1?jmp=docs
40 Chapter 5. Data Model Reference

Data Model Design for MongoDB, Release 3.2.3
On this page
• Manual References (page 41)
• DBRefs (page 42)
MongoDB does not support joins. In MongoDB some data is denormalized, or stored with related data in documents to
remove the need for joins. However, in some cases it makes sense to store related information in separate documents,
typically in different collections or databases.
MongoDB applications use one of two methods for relating documents:
• Manual references (page 41) where you save the _id field of one document in another document as a reference.
Then your application can run a second query to return the related data. These references are simple and
sufficient for most use cases.
• DBRefs (page 42) are references from one document to another using the value of the first document’s _id
field, collection name, and, optionally, its database name. By including these names, DBRefs allow documents
located in multiple collections to be more easily linked with documents from a single collection.
To resolve DBRefs, your application must perform additional queries to return the referenced documents. Many
drivers have helper methods that form the query for the DBRef automatically. The drivers
5
do not automat-
ically resolve DBRefs into documents.
DBRefs provide a common format and type to represent relationships among documents. The DBRef format
also provides common semantics for representing links between documents if your database must interact with
multiple frameworks and tools.
Unless you have a compelling reason to use DBRefs, use manual references instead.
5.2.1 Manual References
Background
Using manual references is the practice of including one document’s _id field in another document. The application
can then issue a second query to resolve the referenced fields as needed.
Process
Consider the following operation to insert two documents, using the _id field of the first document as a reference in
the second document:
original_id = ObjectId()
db.places.insert({
"_id": original_id,
"name": "Broadway Center",
"url": "bc.example.net"
})
db.people.insert({
"name": "Erin",
"places_id": original_id,
"url": "bc.example.net/Erin"
})
5
Some community supported drivers may have alternate behavior and may resolve a DBRef into a document automatically.
5.2. Database References 41

Data Model Design for MongoDB, Release 3.2.3
Then, when a query returns the document from the people collection you can, if needed, make a second query for
the document referenced by the places_id field in the places collection.
Use
For nearly every case where you want to store a relationship between two documents, use manual references (page 41).
The references are simple to create and your application can resolve references as needed.
The only limitation of manual linking is that these references do not convey the database and collection names. If you
have documents in a single collection that relate to documents in more than one collection, you may need to consider
using DBRefs.
5.2.2 DBRefs
Background
DBRefs are a convention for representing a document, rather than a specific reference type. They include the name of
the collection, and in some cases the database name, in addition to the value from the _id field.
Format
DBRefs have the following fields:
$ref
The $ref field holds the name of the collection where the referenced document resides.
$id
The $id field contains the value of the _id field in the referenced document.
$db
Optional.
Contains the name of the database where the referenced document resides.
Only some drivers support $db references.
Example
DBRef documents resemble the following document:
{ "$ref" : <value>, "$id" : <value>, "$db" : <value> }
Consider a document from a collection that stored a DBRef in a creator field:
{
"_id" : ObjectId("5126bbf64aed4daf9e2ab771"),
// .. application fields
"creator" : {
"$ref" : "creators",
"$id" : ObjectId("5126bc054aed4daf9e2ab772"),
"$db" : "users"
}
}
The DBRef in this example points to a document in the creators collection of the users database that has
ObjectId("5126bc054aed4daf9e2ab772") in its _id field.
42 Chapter 5. Data Model Reference

Data Model Design for MongoDB, Release 3.2.3
Note: The order of fields in the DBRef matters, and you must use the above sequence when using a DBRef.
Driver Support for DBRefs
C The C driver contains no support for DBRefs. You can traverse references manually.
C++ The C++ driver contains no support for DBRefs. You can traverse references manually.
C# The C# driver supports DBRefs using the MongoDBRef
6
class and FetchDBRef and
FetchDBRefAs methods.
Haskell The Haskell driver contains no support for DBRefs. You can traverse references manually.
Java The DBRef
7
class provides support for DBRefs from Java.
JavaScriptThe mongo shell’s JavaScript interface provides a DBRef.
Node.js The Node.js driver supports DBRefs using the DBRef
8
class and the dereference
9
method.
Perl The Perl driver supports DBRefs using the MongoDB::DBRef
10
class. You can traverse references
manually.
PHP The PHP driver supports DBRefs, including the optional $db reference, using the MongoDBRef
11
class.
Python The Python driver supports DBRefs using the DBRef
12
class and the dereference
13
method.
Ruby The Ruby driver supports DBRefs using the DBRef
14
class and the dereference
15
method.
Scala The Scala driver contains no support for DBRefs. You can traverse references manually.
Use
In most cases you should use the manual reference (page 41) method for connecting two or more related documents.
However, if you need to reference documents from multiple collections, consider using DBRefs.
5.3 ObjectId
On this page
• Overview (page 43)
• ObjectId() (page 44)
• Examples (page 44)
5.3.1 Overview
ObjectId is a 12-byte BSON type, constructed using:
• a 4-byte value representing the seconds since the Unix epoch,
6
https://api.mongodb.org/csharp/current/html/T_MongoDB_Driver_MongoDBRef.htm
7
https://api.mongodb.org/java/current/com/mongodb/DBRef.html
8
http://mongodb.github.io/node-mongodb-native/api-bson-generated/db_ref.html
9
http://mongodb.github.io/node-mongodb-native/api-generated/db.html#dereference
10
https://metacpan.org/pod/MongoDB::DBRef
11
http://www.php.net/manual/en/class.mongodbref.php/
12
https://api.mongodb.org/python/current/api/bson/dbref.html
13
https://api.mongodb.org/python/current/api/pymongo/database.html#pymongo.database.Database.deref eren ce
14
https://api.mongodb.org/ruby/current/BSON/DBRef.html
15
https://api.mongodb.org/ruby/current/Mongo/DB.html#dereference-instance_method
5.3. ObjectId 43

Data Model Design for MongoDB, Release 3.2.3
• a 3-byte machine identifier,
• a 2-byte process id, and
• a 3-byte counter, starting with a random value.
In MongoDB, documents stored in a collection require a unique _id field that acts as a primary key. MongoDB
uses ObjectIds as the default value for the _id field if the _id field is not specified; i.e. if a document does not
contain a top-level _id field, the MongoDB driver adds the _id field that holds an ObjectId. In addition, if the
mongod receives a document to insert that does not contain an _id field, mongod will add the _id field that holds
an ObjectId.
MongoDB clients should add an _id field with a unique ObjectId. Using ObjectIds for the _id field provides the
following additional benefits:
• in the mongo shell, you can access the creation time of the ObjectId, using the getTimestamp() method.
• sorting on an _id field that stores ObjectId values is roughly equivalent to sorting by creation time.
Important: The relationship between the order of ObjectId values and generation time is not strict within a
single second. If multiple systems, or multiple processes or threads on a single system generate values, within a
single second; ObjectId values do not represent a strict insertion order. Clock skew between clients can also
result in non-strict ordering even for values because client drivers generate ObjectId values.
Also consider the Documents (page 37) section for related information on MongoDB’s document orientation.
5.3.2 ObjectId()
The mongo shell provides the ObjectId() wrapper class to generate a new ObjectId, and to provide the following
helper attribute and methods:
• str
The hexadecimal string representation of the object.
• getTimestamp()
Returns the timestamp portion of the object as a Date.
• toString()
Returns the JavaScript representation in the form of a string literal “ObjectId(...)”.
Changed in version 2.2: In previous versions toString() returns the hexadecimal string representation,
which as of version 2.2 can be retrieved by the str property.
• valueOf()
Returns the representation of the object as a hexadecimal string. The returned string is the str attribute.
Changed in version 2.2: In previous versions, valueOf() returns the object.
5.3.3 Examples
Consider the following uses ObjectId() class in the mongo shell:
44 Chapter 5. Data Model Reference

Data Model Design for MongoDB, Release 3.2.3
Generate a new ObjectId
To generate a new ObjectId, use the ObjectId() constructor with no argument:
x = ObjectId()
In this example, the value of x would be:
ObjectId("507f1f77bcf86cd799439011")
To generate a new ObjectId using the ObjectId() constructor with a unique hexadecimal string:
y = ObjectId("507f191e810c19729de860ea")
In this example, the value of y would be:
ObjectId("507f191e810c19729de860ea")
• To return the timestamp of an ObjectId() object, use the getTimestamp() method as follows:
Convert an ObjectId into a Timestamp
To return the timestamp of an ObjectId() object, use the getTimestamp() method as follows:
ObjectId("507f191e810c19729de860ea").getTimestamp()
This operation will return the following Date object:
ISODate("2012-10-17T20:46:22Z")
Convert ObjectIds into Strings
Access the str attribute of an ObjectId() object, as follows:
ObjectId("507f191e810c19729de860ea").str
This operation will return the following hexadecimal string:
507f191e810c19729de860ea
To return the hexadecimal string representation of an ObjectId(), use the valueOf() method as follows:
ObjectId("507f191e810c19729de860ea").valueOf()
This operation returns the following output:
507f191e810c19729de860ea
To return the string representation of an ObjectId() object (in the form of a string literal ObjectId(...)), use
the toString() method as follows:
ObjectId("507f191e810c19729de860ea").toString()
This operation will return the following string output:
ObjectId("507f191e810c19729de860ea")
5.3. ObjectId 45

Data Model Design for MongoDB, Release 3.2.3
5.4 BSON Types
On this page
• Comparison/Sort Order (page 46)
• ObjectId (page 47)
• String (page 47)
• Timestamps (page 48)
• Date (page 48)
BSON is a binary serialization format used to store documents and make remote procedure calls in MongoDB. The
BSON specification is located at bsonspec.org
16
.
BSON supports the following data types as values in documents. Each data type has a corresponding number and
string alias that can be used with the $type operator to query documents by BSON type.
Type Number Alias Notes
Double 1 “double”
String 2 “string”
Object 3 “object”
Array 4 “array”
Binary data 5 “binData”
Undefined 6 “undefined” Deprecated.
Object id 7 “objectId”
Boolean 8 “bool”
Date 9 “date”
Null 10 “null”
Regular Expression 11 “regex”
DBPointer 12 “dbPointer”
JavaScript 13 “javascript”
Symbol 14 “symbol”
JavaScript (with scope) 15 “javascriptWithScope”
32-bit integer 16 “int”
Timestamp 17 “timestamp”
64-bit integer 18 “long”
Min key -1 “minKey”
Max key 127 “maxKey”
To determine a field’s type, see check-types-in-shell.
If you convert BSON to JSON, see the Extended JSON reference.
5.4.1 Comparison/Sort Order
When comparing values of different BSON types, MongoDB uses the following comparison order, from lowest to
highest:
1. MinKey (internal type)
2. Null
3. Numbers (ints, longs, doubles)
4. Symbol, String
16
http://bsonspec.org/
46 Chapter 5. Data Model Reference

Data Model Design for MongoDB, Release 3.2.3
5. Object
6. Array
7. BinData
8. ObjectId
9. Boolean
10. Date
11. Timestamp
12. Regular Expression
13. MaxKey (internal type)
MongoDB treats some types as equivalent for comparison purposes. For instance, numeric types undergo conversion
before comparison.
Changed in version 3.0.0: Date objects sort before Timestamp objects. Previously Date and Timestamp objects sorted
together.
The comparison treats a non-existent field as it would an empty BSON Object. As such, a sort on the a field in
documents { } and { a: null } would treat the documents as equivalent in sort order.
With arrays, a less-than comparison or an ascending sort compares the smallest element of arrays, and a greater-than
comparison or a descending sort compares the largest element of the arrays. As such, when comparing a field whose
value is a single-element array (e.g. [ 1 ]) with non-array fields (e.g. 2), the comparison is between 1 and 2. A
comparison of an empty array (e.g. [ ]) treats the empty array as less than null or a missing field.
MongoDB sorts BinData in the following order:
1. First, the length or size of the data.
2. Then, by the BSON one-byte subtype.
3. Finally, by the data, performing a byte-by-byte comparison.
The following sections describe special considerations for particular BSON types.
5.4.2 ObjectId
ObjectIds are: small, likely unique, fast to generate, and ordered. These values consists of 12-bytes, where the first
four bytes are a timestamp that reflect the ObjectId’s creation. Refer to the ObjectId (page 43) documentation for more
information.
5.4.3 String
BSON strings are UTF-8. In general, drivers for each programming language convert from the language’s string format
to UTF-8 when serializing and deserializing BSON. This makes it possible to store most international characters in
BSON strings with ease.
17
In addition, MongoDB $regex queries support UTF-8 in the regex string.
17
Given strings using UTF-8 character sets, using sort() on strings will be reasonably correct. However, because internally sort() uses the
C++ strcmp api, the sort order may handle some characters incorrectly.
5.4. BSON Types 47

Data Model Design for MongoDB, Release 3.2.3
5.4.4 Timestamps
BSON has a special timestamp type for internal MongoDB use and is not associated with the regular Date (page 48)
type. Timestamp values are a 64 bit value where:
• the first 32 bits are a time_t value (seconds since the Unix epoch)
• the second 32 bits are an incrementing ordinal for operations within a given second.
Within a single mongod instance, timestamp values are always unique.
In replication, the oplog has a ts field. The values in this field reflect the operation time, which uses a BSON
timestamp value.
Note: The BSON timestamp type is for internal MongoDB use. For most cases, in application development, you will
want to use the BSON date type. See Date (page 48) for more information.
If you insert a document containing an empty BSON timestamp in a top-level field, the MongoDB server will replace
that empty timestamp with the current timestamp value. For example, if you create an insert a document with a
timestamp value, as in the following operation:
var a = new Timestamp();
db.test.insert( { ts: a } );
Then, the db.test.find() operation will return a document that resembles the following:
{ "_id" : ObjectId("542c2b97bac0595474108b48"), "ts" : Timestamp(1412180887, 1) }
If ts were a field in an embedded document, the server would have left it as an empty timestamp value.
Changed in version 2.6: Previously, the server would only replace empty timestamp values in the first two fields,
including _id, of an inserted document. Now MongoDB will replace any top-level field.
5.4.5 Date
BSON Date is a 64-bit integer that represents the number of milliseconds since the Unix epoch (Jan 1, 1970). This
results in a representable date range of about 290 million years into the past and future.
The official BSON specification
18
refers to the BSON Date type as the UTC datetime.
Changed in version 2.0: BSON Date type is signed.
19
Negative values represent dates before 1970.
Example
Construct a Date using the new Date() constructor in the mongo shell:
var mydate1 = new Date()
Example
Construct a Date using the ISODate() constructor in the mongo shell:
var mydate2 = ISODate()
18
http://bsonspec.org/#/specification
19
Prior to version 2.0, Date values were incorrectly interpreted as unsigned integers, which affected sorts, range queries, and indexes on Date
fields. Because indexes are not recreated when upgrading, please re-index if you created an index on Date values with an earlier version, and dates
before 1970 are relevant to your application.
48 Chapter 5. Data Model Reference

Data Model Design for MongoDB, Release 3.2.3
Example
Return the Date value as string:
mydate1.toString()
Example
Return the month portion of the Date value; months are zero-indexed, so that January is month 0:
mydate1.getMonth()
5.4. BSON Types 49
