
Module 5:
Dictionary ADT (Hash table)
Dr. Natarajan Meghanathan
Professor of Computer Science
Jackson State University
Jackson, MS 39217
E-mail: natarajan.meghanathan@jsums.edu

Dictionary ADT
• Models data as a collection of key-value pairs.
– The Keys are unique
– A value has a unique key and is accessed in the
dictionary using that key
• Operations
– Insert: The addition of a key-value pair
– Delete: The removal of a key-value pair
– Find: Lookup the existence of a key-value pair
– isEmpty: Whether the dictionary is empty
• Implementations: Hash tables, Binary search
trees
Hash table
• Maps the elements (values) of a collection to a unique key and
stores them as key-value pairs.
• Hash table of size m (where m is the number of unique keys,
ranging from 0 to m-1) uses a hash function H(v) = v mod m
• The hash value (a.k.a. hash index) for an element v is H(v) = v mod
m and corresponds to one of the keys of the hash table.
• The size of the Hash table is typically a prime integer.
• Example: Consider a hash table of size 7. Its hash function is H(v) =
v mod 7.
• Let an array A = {45, 67, 89, 45, 85, 12, 88, 90, 13, 14}
Value, v 45 67 89 45 85 12 88 90 13 14
H(v) = v mod 7 3 4 5 3 1 5 4 6 6 0
0 1 2 3 4 5 6
45
45
67
88
89
12
85
90
13
14
We will implement Hash table as
an array of singly linked lists

Space-Time Tradeoff
• Note: At the worst case, there could be only one linked
list in the hash table (i.e., all the elements map to the
same key).
• On average, we expect the ‘n’ elements to be evenly
divided across the ‘m’ keys, so that the length of a linked
list is n/m. Nevertheless, for a hash table of certain size
(m), ‘n’ is the only variable.
• Space complexity: Θ(n)
– For an array of ‘n’ elements, we need to allocate space for ‘n’
nodes (plus the ‘m’ head node) across the ‘m’ linked lists.
– Since usually, n >> m, we just consider the overhead associated
with storing the ‘n’ nodes
• Time complexity:
– Insert/Delete/Lookup: O(n), we may have to traverse the entire
linked list
– isEmpty: O(m), we have to check whether each index in the
Hash table has an empty linked list or not.
Example: Number of Comparisons
Array, A = {45, 23, 11, 78, 89, 44, 22, 28, 41, 30}
H(v) = v mod 7
0 1 2 3 4 5 6
Hash table
4523
44
30
1178
22
8928 41
Average Number of Comparisons for a Successful Search (Hash table)
Successful
Search, # comparisons
1
2
3
= (7*1) + (2*2) + (1*3) 14
---------------------------- = ------- = 1.4
10 10
Worst Case Number of Comparisons for a Successful Search (Hash table) = 3
Worst Case Number of Comparisons for an Unsuccessful Search (Hash table) = 3
Example: Number of Comparisons
Array, A = {45, 23, 11, 78, 89, 44, 22, 28, 41, 30}
H(v) = v mod 7
0 1 2 3 4 5 6Hash table
4523
44
30
1178
22
8928 41
Average Number of Comparisons
for a Successful Search (Hash table)
Successful
Search, # comparisons
1
2
3
(7*1) + (2*2) + (1*3) 14
= ---------------------------- = ------- = 1.4
10 10
Worst Case Number of Comparisons
For a Successful Search
For an unsuccessful Search
Average Number of Comparisons
for a Successful Search (Array)
1 + 2 + 3 + … + 10 10*11/2
= --------------------------- = ------------- = 5.5
10 10
Hash table Array
3 10
3 10

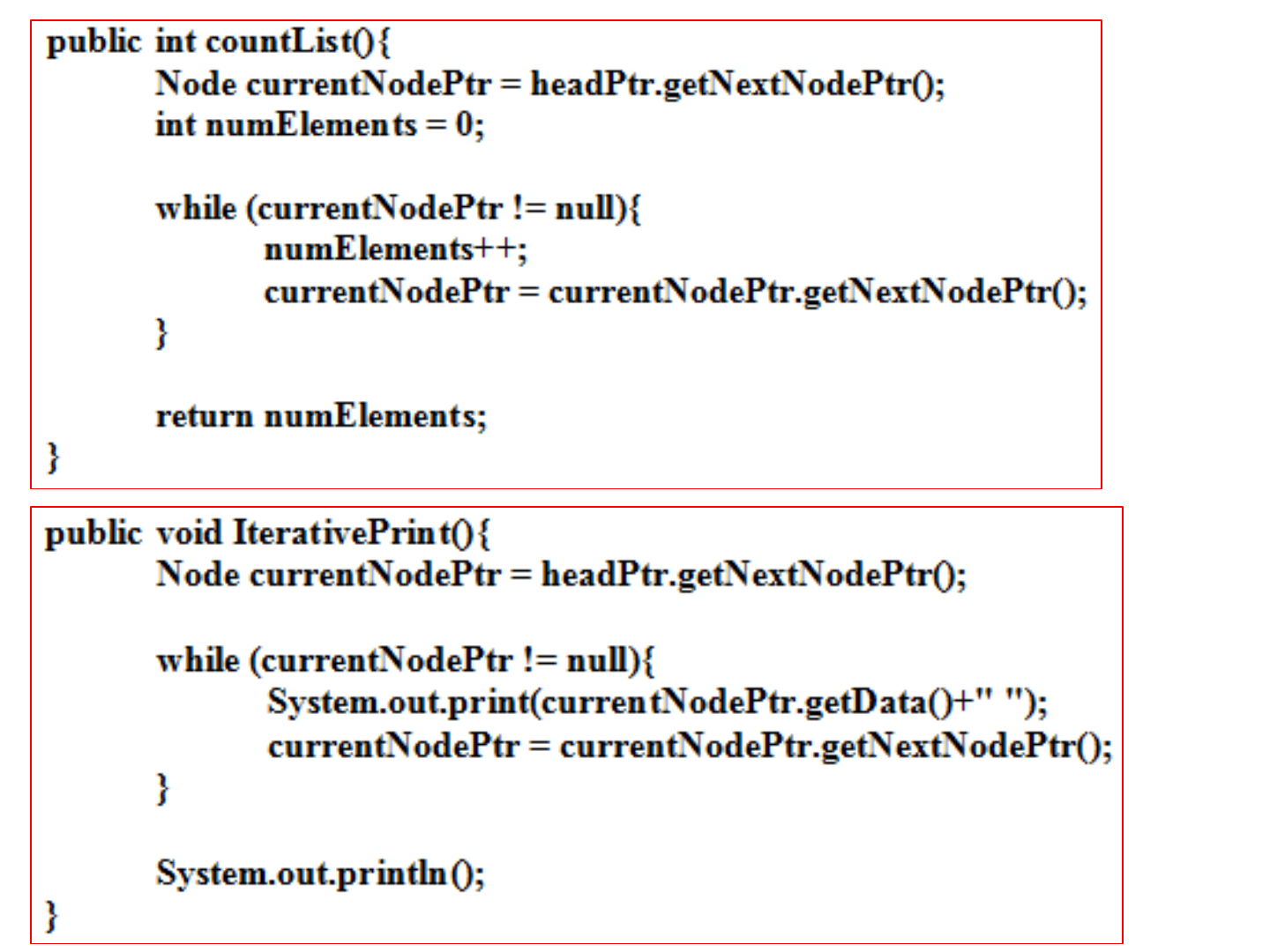
Review of Singly Linked List
Class List
C++
Class List
Java

insert(int) C++
insert(int) Java

deleteElement(int)
C++

deleteElement(int)
Java

C++
Java

C++
Java

Hash table Implementation (Code: 5.1)
Class Hashtable
C++
Class Hashtable
Java

Class Hashtable
C++
Just to delete the first occurrence
of the data in the Linked List
To delete all the entries for the data
in the Linked List

Class Hashtable
Java
Just to delete the first occurrence
of the data in the Linked List
To delete all the entries for the data
in the Linked List

Sample Applications of Hash table
• To test whether a test sequence is a
permutation of a given sequence
• To print the unique elements in an array
• To find the union of two linked lists

Permutation Check (Code 5.2)
• Given a sequence of integers (as a string)
– Use string tokenizer to parse the string, extract the
individual integers and store them in a hash table
• Given the test sequence of integers (also a
string)
– Use string tokenizer to parse the string and extract the
individual integers
• For each integer in the test sequence, check if it is in the hash
table.
– If so, delete it (just delete the first occurrence of the integer in the
appropriate linked list of the hash table)
– Otherwise, STOP and say the test sequence is not a permutation
of the original sequence
• If the hash table is empty after the test sequence is processed,
print that the test sequence is a permutation of the original
sequence; otherwise, it is not a permutation of the original.

Hashtable: isEmpty( )
Code 5.2: C++
// If even one linked list is not empty, return false
// (i.e., the hash table is not empty)
// If all the linked lists are empty, return true
// (i.e., the hash table is empty)
Code 5.2: Java

Code 5.2 (C++)
// Input the original integer sequence as a
// comma separated list
// Example: 45, 23, 12, 23, 90
// Input the test sequence likewise
// Example: 12, 23, 45, 90, 23
// Input the size of the hash table and
// Initialize a hash table of that size
// Code for tokenizing the original
// integer sequence and extracting
// the individual integers
// Insert the extracted integers in the hash table

Code 5.2 (C++)
// Print the contents of the hash table
// Code to string tokenize the
// test integer sequence and extract
// the individual integers
// Check whether a test integer is in the
// hash table; if so, delete it.
// If not in the hash table, print the test
// sequence is not a permuted seq. STOP!
// equivalent to stopping the program right away!
// If the hash table is empty when we finish processing the test sequence, it implies
// there exists an element in the original sequence for every element in the test
// sequence and all of these elements were deleted. Hence, they are a permutation

Code 5.2 (Java)
// Input the original integer sequence as a
// comma separated list
// Example: 45, 23, 12, 23, 90
// Input the test sequence likewise
// Example: 12, 23, 45, 90, 23
// Input the size of the
// hash table and
// Initialize a hash table of
// that size
// Code for tokenizing the original
// integer sequence and extracting
// the individual integers
// Insert the extracted integers in the hash table

Code 5.2 (Java)
// Print the contents of the hash table
// Code to string tokenize the
// test integer sequence and
// extract the individual integers
// Check whether a test integer is in the
// hash table; if so, delete it.
// If not in the hash table, print the test
// sequence is not a permuted seq. STOP!
// equivalent to stopping
// the program right away!
// If the hash table is empty when we finish processing the test sequence, it implies
// there exists an element in the original sequence for every element in the test
// sequence and all of these elements were deleted. Hence, they are a permutation

Printing the Unique Elements
(Code 5.3)
• Given an array A[0…n-1] that may have elements
appearing more than once, we could use the hash table
to store the unique elements and print them.
• For every element A[i], with 0 ≤ i ≤ n-1, we store the
element A[i] in the hash table the first time we come
across it as well as print it.
• Hence, for every element A[i], with 0 ≤ i ≤ n-1, we check
if A[i] is already in the hash table.
– If A[i] is not already in the hash table, it implies A[i] has not been
seen before: so, we print it out as well as insert in the hash table.
– If A[i] is already in the hash table, it implies we have already
printed it out and should not be printed again.
• The time complexity of the algorithm is dependent on the
time to check whether a particular element is in the hash
table or not for all values of the array index. If this could
be done in Θ(1) time per element, the asymptotic time
complexity of the algorithm is Θ(n).

Code 5.3 (C++)
// Input the number of elements to store in the array
// Input the maximum value for an element
// Input the number of indexes in the hash table
// Initialize the random number generator
// Generate the random elements
// and store them in the array as well as
// print them

Code 5.3 (C++)
// Initialize the
// Hash table
// For an element array[index]: check if it is in the
// hashTable. If it is not there, it implies the element
// has not been seen before and print it as well as add
// it to the hashTable.
// If the element is already there in the hashTable,
// it implies it is the duplicate entry for the element and
// is not printed.

Code 5.3 (Java)
// Input the number of elements to store in the array
// Input the maximum value for an element
// Input the number of indexes in the hash table
// Initialize the random number generator
// Generate the random elements
// and store them in the array as well as
// print them
// Create an object of class Scanner to get inputs from the user

Code 5.3 (Java)
// Initialize the Hash table
// For an element array[index]: check if it is in the
// hashTable. If it is not there, it implies the element
// has not been seen before and print it as well as add
// it to the hashTable.
// If the element is already there in the hashTable,
// it implies it is the duplicate entry for the element and
// is not printed.

Find the Union of two Linked Lists
(Code 5.4)
• Let L1 and L2 be the two linked lists and unionList be the
union of the two lists
• unionList is initially empty and an element is to be
included only once in this list (i.e., elements with
duplicate entries in L1 or L2 are included only once in
the unionList).
• We populate the contents of L1 in a hash table and
unionList:
– An element is added to both the hash table and unionList if the
element is not in the hash table.
• We go through list L2, element by element. If an element
in L2 is not in the hash table (it implies the element is not
in L1 and unionList either), then it is included in the hash
table as well as the unionList.

Code 5.4 (C++)
// Assume the two linked lists have the same number of elements
// The maximum value that could be for an element in the two lists
// is also the same
// Input the number of indexes for the
// Hash table
// Initialize the random number generator
// generate random integers and
// populate the firstList
// generate random integers and
// populate the secondList

Code 5.4 (C++)
// The unionList will have only unique
// elements
// Scan through the firstList and
// insert an element in both the
// hash table and unionList if the
// element is not already in
// the hash table
// Scan through the secondList
// If an element in the secondList
// is not in the hash table, it implies
// the element is not in the unionList
// either and hence add the element
// to both the unionList and the
// hash table

Code 5.4 (Java)
// Assume the two linked lists have the same
// number of elements. The maximum value that
// could be for an element in the two lists is also
// the same
// Input the number of indexes for the
// Hash table
// Initialize the random number generator
// generate random integers and
// populate the firstList
// generate random integers and
// populate the secondList

Code 5.4 (Java)
// The unionList will have only unique
// elements
// Scan through the firstList and
// insert an element in both the
// hash table and unionList if the
// element is not already in
// the hash table
// Scan through the secondList
// If an element in the secondList
// is not in the hash table, it implies
// the element is not in the unionList
// either and hence add the element
// to both the unionList and the
// hash table
